Die Dateninterpretation ist ein wichtiger Bestandteil der Statistik. Lisa Jödicke beschreibt am Beispiel des «Hungry Judg e Effect», was es dabei zu beachten gibt und was alles schiefgehen kann.
e Effect», was es dabei zu beachten gibt und was alles schiefgehen kann.
Der vorliegende Beitrag entstand 2023 im Rahmen der Sommerakademie «Stupid Statistics?!? Durchblick behalten im Daten-Dschungel der Gegenwart» der Schweizerischen Studienstiftung und wurde redaktionell begleitet von Reatch. Der Beitrag gibt die persönliche Meinung der Autorin wieder und entspricht nicht zwingend derjenigen von Reatch oder der Schweizerischen Studienstiftung. Erstmals erschienen im Reatch-Blog.
Wenn Richter:innen hungrig sind, urteilen sie strenger, so das Fazit einer Studie von Danziger et al. aus dem Jahre 2011. [1] Die Autoren konnten nämlich beobachten, dass Gerichtsurteile über vorzeitige Entlassungen aus dem Gefängnis oder über Lockerungen von Haftbedingungen vor der Mittagszeit häufiger negativ ausfielen als zu anderen Tageszeiten. Dieser «Hungry Judge Effect» fand breite Resonanz und die dazugehörige Publikation wurde mehrfach zitiert. [2] Es stellte sich nachträglich jedoch heraus, dass die Studie nicht tief genug ging und der «Hungry Judge Effect» sich mit den publizierten Daten kaum belegen liess: Der Hunger der Richter war nicht die einzige plausible Erklärung für die strengeren Urteile vor der Mittagszeit. [2] Im Kern dieser Kontroverse steht die Kunst der Dateninterpretation.
Doch was versteht man genau unter Dateninterpretation? Bei der Arbeit mit Daten durchläuft man mehrere Phasen: Von der Erhebung über die Analyse bis hin zur Interpretation und Vermittlung. Diese Phasen, insbesondere die Datenanalyse und die Dateninterpretation, sind eng miteinander verknüpft und überschneiden sich in der Praxis jeweils teilweise. Dennoch lassen sich Unterschiede erkennen: Während es bei der Datenanalyse darum geht, die gesammelten Daten mit der passenden statistischen Methode zu analysieren, konzentriert sich die Dateninterpretation darauf, was aus den analysierten Daten zu schliessen ist. Es wird untersucht, ob und wie Variablen miteinander zusammenhängen (Korrelation) und welche Variablen einander beeinflussen können (Kausalität). Die Daten müssen dabei stets im Kontext der konkreten Fragestellung und auch der Datenerhebung betrachtet werden, damit ihnen eine wissenschaftliche oder praktische Bedeutung zugewiesen werden kann. In einem letzten Schritt werden basierend darauf mögliche Handlungsschritte abgeleitet. Diese Handlungsschritte können je nach Kontext ganz unterschiedlich ausfallen, auch wenn ihnen dieselbe mathematische Datenanalyse zugrunde liegt. Wenn beispielsweise die Analyse der Niederschlagsmengen ergibt, dass es in den letzten Jahren einen starken Anstieg gegeben hat, dann ergeben sich daraus für eine ländliche, naturnahe Region andere Handlungsschritte als für eine Grossstadt mit vielen versiegelten Böden.
Voraussetzungen für eine korrekte Dateninterpretation
Damit Daten richtig interpretiert werden, sind einige Voraussetzungen zu erfüllen. Zuerst ist es wichtig zu wissen, woher die Daten stammen und wie sie erhoben wurden. Rückverfolgbare Daten mit vertrauenswürdiger Herkunft sind eine gute Voraussetzung dafür, dass sie sich verlässlich interpretieren lassen. Ist die Herkunft der Daten bekannt, so können sie in den Kontext ihrer Erhebung eingeordnet werden. In diesem Zusammenhang ist es immer wichtig, sich zu vergegenwärtigen, dass Daten nicht “für sich selbst sprechen” können. [3] In der Studie von Danziger et al. wurden während zehn Monaten 1112 Gerichtsentscheide von acht Richter:innen in Israel untersucht. Die Richter:innen entschieden aufgrund von Anträgen der Insassen, ob deren Gefängnisstrafe verkürzt werden sollte. Alle Daten über diese Entscheide kamen direkt vom Gericht oder wurden von Danziger et al. selbst erhoben. Somit können sie als rückverfolgbar und vertrauenswürdig betrachtet werden.
Ebenfalls wichtig zu prüfen ist, ob die Daten vollständig sind, oder ob es wesentliche Lücken gibt. Idealerweise dienen alle erhobenen und analysierten Daten als Grundlage für die Interpretation. Gibt es Lücken bei der Erhebung oder Auswertung, müssen zumeist Annahmen getroffen werden, die auch die Interpretation beeinflussen. Bei Medikamentenstudien mit Kontroll- und Testgruppen kommt es beispielsweise regelmässig vor, dass Patienten im Verlaufe der Studie ihre Teilnahme zurückziehen. Geschieht dieser Rückzug zufällig über beide Gruppen verteilt, ist das für die Interpretation weniger problematisch, als wenn nur eine der beiden Gruppen betroffen ist. Ziehen sich beispielsweise ausschliesslich Patienten in der Testgruppe zurück, könnte es sein, dass das Medikament zu wenig wirksam ist oder unangenehme Nebenwirkungen verursacht. So könnte es sein, dass nur jene Patienten bis zum Ende der Studie in der Testgruppe verbleiben, bei denen das Medikament besonders gut wirkt oder keine Nebenwirkungen verursacht. Diese Überlegungen gilt es bei der Interpretation der Daten zwingend zu berücksichtigen. Im Fall von Danziger et al. flossen alle erhobenen Daten in die Analyse mit ein. Allerdings stammen die Daten nur von einem Gerichtshof und lassen sich nicht ohne weitere Annahmen auf andere Gerichtshöfe übertragen.
Natürlich spielt auch die Aktualität der Daten eine entscheidende Rolle. Der Erhebungszeitpunkt muss immer bekannt sein, vor allem wenn die Daten schon älter sind, oder wenn unterschiedlich alte Daten miteinander verglichen werden. Im Bereich der Schadstoffgrenzwerte kann die Verwendung veralteter Daten beispielsweise Gefahren bergen: Die Schädlichkeit von Asbest wird immer noch untersucht und die Vorschriften bezüglich der Grenzwerte werden immer wieder verschärft. [4] Würde eine Schutzvorschrift für Arbeiter:innen nun basierend auf älteren Daten aufgestellt, so würde diese eine zu grosse Aussetzung von Asbest erlauben, und könnte somit Arbeiter:innen gefährden. Im Falle der Studie von Danziger et al. stammen die Daten der untersuchten Gerichtsfälle alle aus dem Jahr 2010 und wurden im folgenden Jahr veröffentlicht. Die Daten waren also aktuell.
Ebenfalls entscheidend ist die Frage, ob es sich um eine experimentelle oder eine beobachtende Datenerhebung handelt (siehe dazu auch den Beitrag aus der «Stupid Statistics?!» Reihe zur Datenerhebung). Bei einer beobachtenden Studie werden Daten aus der «realen Welt» untersucht, ohne dass diese beeinflusst wird. Im Gegensatz dazu werden die Daten bei einem Experiment zumeist unter eng kontrollierten Bedingungen erhoben, sodass sich auch einfache Kausalzusammenhänge erkennen lassen. Weil die Studie von Danziger et al. eine beobachtende Studie ist, deren Daten nicht repräsentativ über verschiedene Gerichtshöfe erhoben wurden, lassen sich ohne zusätzliche Annahmen weder Kausalzusammenhänge noch verallgemeinernde Aussagen davon ableiten.
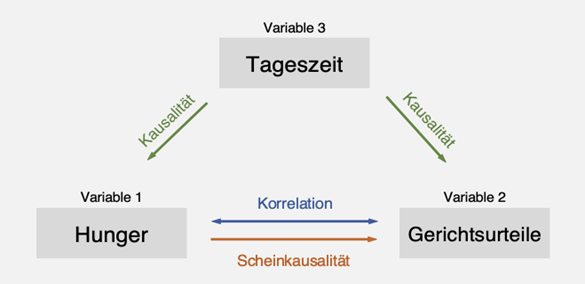
Einer der häufigsten Fehler bei der Interpretation von Daten ist es jedoch, Korrelation mit Kausalität zu verwechseln. Dies geschieht dann, wenn die statistische Korrelation, also ein linearer Zusammenhang, zwischen zwei Variablen fälschlicherweise als kausaler Zusammenhang interpretiert wird. Im Beispiel des «Hungry Judge Effektes» sind die beiden zu untersuchenden Variablen der angenommene Hunger der Richter:innen und der Anteil abgelehnter Anträge. Nimmt man an, dass der Hunger gegen Mittag zunimmt, und vergleicht man dies mit der zunehmenden Rate von abgelehnten Anträgen, so korrelieren die Variablen: Die Häufigkeit der abgelehnten Anträge nimmt parallel zum Hunger zu. Wenn die Veränderung einer Variablen die Veränderung einer anderen Variable bewirkt, so sprechen wir von Kausalität oder auch vom Ursache-Wirkungs-Prinzip.
Es wirkt so, als mache der Hunger die Richter:innen strenger, der Hunger scheint also die Gerichtsurteile kausal zu beeinflussen. Was jedoch bei der Studie nicht miteinbezogen wurde, ist, dass die Gerichtsfälle nicht in zufälliger Reihenfolge über den Tag verteilt wurden. Die beiden Wissenschaftler Weinshall-Margel und Shapard untersuchten, wie die in der Studie von Danziger et al. betrachteten Fälle über den Tag verteilt worden waren, und stellten fest: Gesuche von Häftlingen ohne Anwaltsvertretung wurden eher kurz vor dem Mittag behandelt und bei den Fällen mit Anwälten konnten diese die Reihenfolge selbst wählen und tendierten eventuell dazu, ihre schwächeren Fälle näher an der Mittagspause zu positionieren. [5] Es lässt sich also feststellen, dass es sich in diesem Fall um eine fälschlich interpretierte Kausalität, eine sogenannte Scheinkausalität handelt. [6] Die beiden Variablen beeinflussten sich nicht gegenseitig, vielmehr gab es noch eine dritte Variable, die beide beeinflusste: die Tageszeit (vgl. Abb. 1). [7]
Fazit
Um all diese Voraussetzungen zu erfüllen, müssen natürlich die verschiedenen Aspekte der Datenanalyse bekannt sein: Datenkompetenz (oder Data Literacy) beschreibt die Fähigkeiten, mit Daten sachgerecht umzugehen, sie zu interpretieren und die Ergebnisse zu präsentieren. [8] Dies ist eine Voraussetzung für diejenigen, die die Dateninterpretation durchführen, es ist aber auch eine Voraussetzung für die «Endkonsument:innen». Datenwissenschaftlerin Katharina Schüller meint dazu, die Datenkompetenz sei nicht nur für diejenigen wichtig, die relevante Entscheidungen treffen und daher verstehen müssen, was die Daten aussagen und was die Evidenz ist. Sondern Datenkompetenz sei auch relevant für alle Bürger:innen, die oft Daten weiterverbreiten, ohne Wissen über die Auswirkungen. [9] Souveräne Dateninterpretation ist also immer kontextabhängig und muss auch geübt werden. Um Datenkompetenz zu fördern, könnte sie schon früh in der Schule gelehrt werden, sodass die Bevölkerung Daten selbstständig und kritisch interpretieren kann.[9]
